

Unlocking high-fidelity, reliable AI for code generation and engineering workflows is a massive opportunity.
 Listen to this article >
Listen to this article >
Engineering tasks are well suited for AI augmentation or replacement for a few reasons: (i) coding inherently requires engineers to break a problem down into smaller, more manageable tasks; (ii) there’s plenty of existing training data; (iii) tasks require a mix of judgment and rules-based work; (iv) solutions leverage composable modules (OSS libraries etc); and (v) in some cases the result of one’s work can be empirically tested for correctness. This means reliably accurate AI coding tools can deliver quantifiable value.
Given these factors, attempts at AI coding tools have exploded in just the past year. But there are still many open questions about the technical unlocks that must be solved to make coding tools that work as well as (or better than) human engineers in a production setting.
In this post, I’ll frame the three approaches we at Greylock are seeing in the startup ecosystem and the three open challenges facing these tools:
- How do we create more powerful context awareness?
- How do we get AI agents to work better for E2E coding tasks?
- Does owning a code-specific model lead to long-term differentiation?
Current State of Market
In the past year, we’ve seen startups take three approaches:
- AI copilots and chat interfaces to enhance engineering workflows by sitting alongside engineers in the tools where they work.
- AI agents that can replace engineering workflows by performing engineering tasks end-to-end.
- Code-specific foundation models. These are bespoke models trained with code-specific data, and are vertically-integrated with user-facing applications.
Even before the overarching questions are answered, we believe each of the above approaches can deliver meaningful impact in the near term. Let’s take a closer look at each one.


1. Enhancing Existing Workflows
Today, the vast majority of AI code startups are taking the shape of in-IDE co-pilots or chat interfaces to enhance engineering workflows. While companies like Tabnine have been working on code assistants for many years, the big moment for coding AI tools came with the release of GitHub Copilot in 2021. Since then, we have seen a flurry of startups going after the various jobs to be done by engineers.
Startups finding traction are going after workflows centered around code generation or code testing. This is because:
- They are core parts of an engineer’s job
- They can require relatively low context to be sufficiently useful
- In most cases, they can be bundled within a single platform
- In a world where reliability is scarce, putting outputs right in front of the user (i.e. in the IDE) allows them to take ownership of any corrections required
The elephant in the room is the challenge of going after GitHub Copilot, which already has considerable distribution and mindshare (congratulations to Devin who just secured their own partnership with Microsoft). Startups are working around this by looking for pockets of differentiation in which to ground their wedge. For example, Codeium is taking an enterprise-first approach, while Codium is starting with code testing and reviewing and expanding from there.
We also believe there is a strong opportunity for tools going after tasks like code refactoring, code review, and software architecting. These can be more complex as they not only require a larger surface area of understanding within the code, but also an understanding of a graph of knowledge between different files, knowledge of external libraries, understanding of the business context, the end-usage patterns of the software, and the complex selection of tools.
Regardless of the wedge, one of the recurring challenges we’re seeing at this layer is how to access relevant context to solve wider-reaching tasks within a company’s codebase. Exactly how that’s done is an open question, which we explore in the last section in this post.
2. AI Coding Agents
If augmenting engineering workflow is valuable, an even larger opportunity is figuring out what workflows can be completely replaced.
AI coding products that can perform engineering tasks end-to-end – and can work in the background while the human engineer does something else – would create an entirely new level of productivity and innovation. A giant leap beyond AI co-pilots, AI coding agents could take us from a realm of selling tooling to selling labor. In a world where coding agents get very good, you could have a single human supervising multiple “AI engineers” in parallel.
The fundamental capability of an AI agent isn’t just about predicting the next word in a line of code. It needs to couple that with the ability to carry out complex tasks with upwards of dozens of steps, and, like an engineer, think about the product from the user perspective. For example, if prompted to fix a bug, it needs to know its location, the nature of its problem, how it affects the product, any downstream changes that might result from fixing the bug, and much more before it can even take the first action. The context must come from something like ingesting Jira tickets, larger chunks of the codebase, and other sources of information. Being able to write detailed code specs and accurate code planning will become central to adopting AI engineers.
Companies and projects we have seen in this space include (but are not limited to) Devin, Factory, CodeGen, SWE-Agent, OpenDevin, AutoCodeRover, Trunk, and more.
The question then is: what needs to be done for agents to be able to complete a larger portion of tasks end to end? This is addressed in my open questions section.
3. Code-Specific Foundation Model Companies
A few founders believe that in order to build long-term differentiation at the code app layer, you need to own a code-specific model that powers it.
It’s not an unreasonable suggestion, but it seems there are a few open questions that have steered other startups away from this capital-intensive approach – primarily that it’s unclear whether a code-specific model will get leapfrogged by improvements at the base model layer. I’ll go into this topic further in the open questions section.
First, let’s recall that most foundational LLMs are not trained exclusively on code, and many existing code-specific models like CodeLlama and AlphaCode are created by taking an LLM base model, giving it millions of points of publicly available code, and fine-tuning it to programming needs.
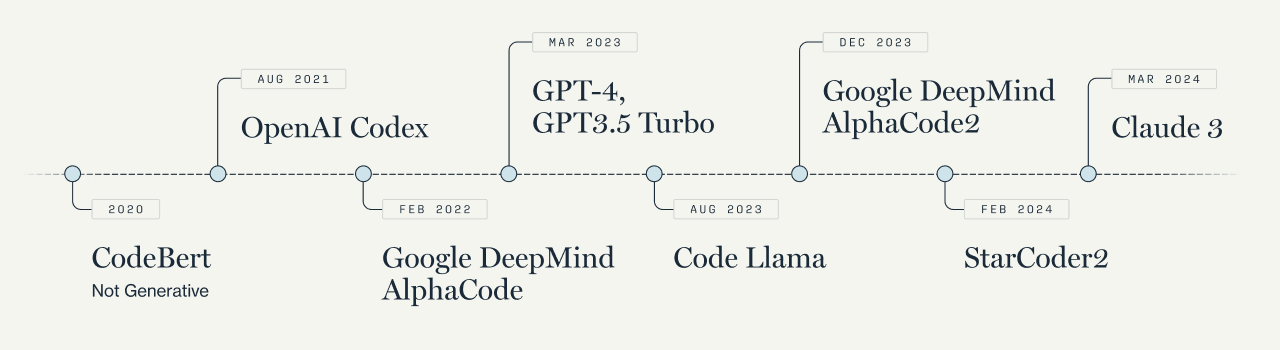

Note: timeline shows only a select set of code-specific models and LLMs that are heavily used for coding use cases
Today, startups like Magic, Poolside, and Augment are trying to take this a step further by training their own code-specific models by generating their own code data and using human feedback on the coding examples (Poolside calls this “Reinforcement Learning from Code Execution Feedback”). The thesis is that doing this will lead to better output, reduce reliance on GPT-4 or other LLMs, and ultimately, create the most durable moat possible.
The core question here is whether a new team can out-pace frontier model improvements. The base model space is moving so fast that if you do try to go deep on a code-specific model, you are at risk of a better base model coming into existence and leapfrogging you before your new model is done training. Given how capital intensive model training is, there’s a lot of time and money at risk if you get this question wrong.
I know some teams are taking the (very appealing) approach of doing code specific fine-tuning for specific tasks on top of the base models, allowing to benefit from the progress of base models while improving performance on code tasks – I will go into this in Open Question 3.
Open Questions
Regardless of the approach one takes, there are technical challenges that need to be solved to unlock reliable code generation tools with low latency and good UX:
- How do we create more powerful context awareness?
- How do we get AI agents to work better for E2E coding tasks?
- Does owning the model and model infra lead to a long term differentiated product?
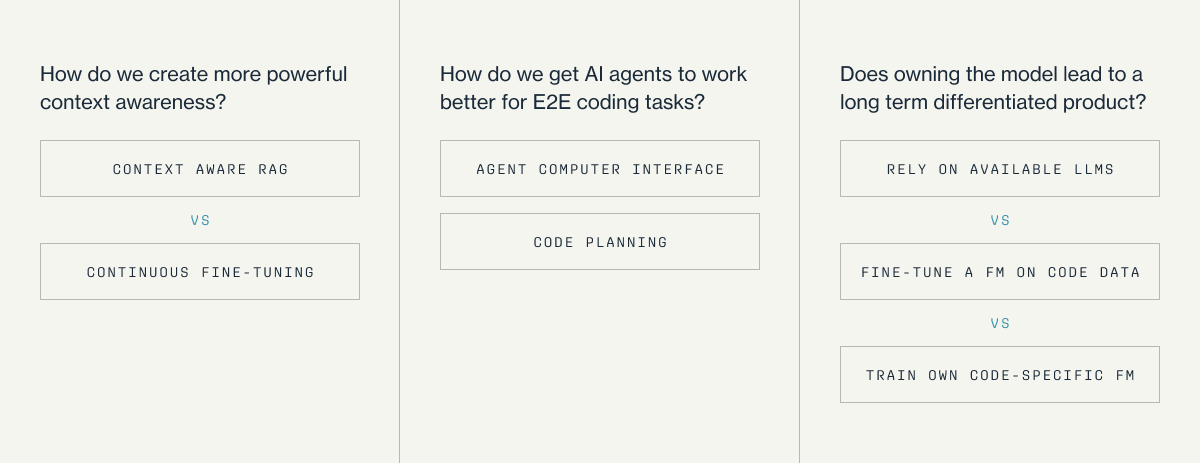
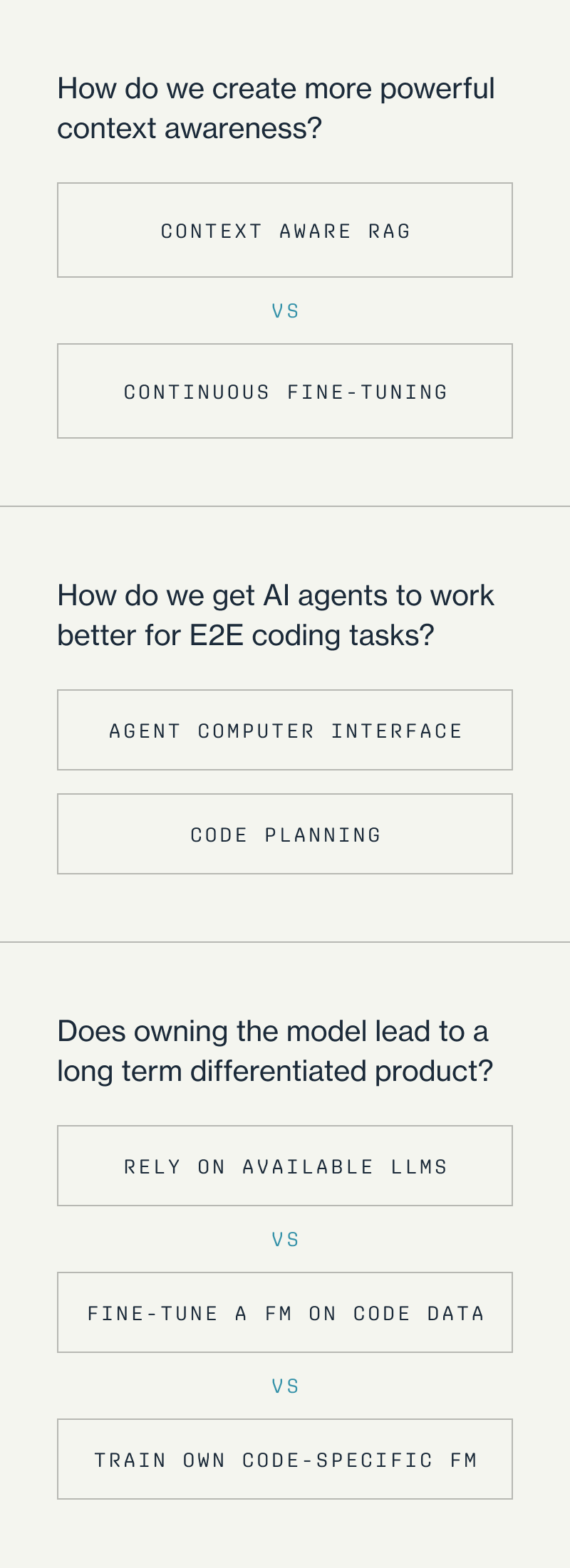
Open Question 1: How do we create more powerful context awareness?
The crux of the context issue is the fact that certain coding tasks require pieces of information and context that live outside of the open file an engineer is working in, and can’t be accessed by simply increasing the context window size. Retrieving those pieces of information from different parts of the codebase (and even external to it) is not only challenging, but can increase latency, which is lethal in an instant auto-complete world. This poses a great opportunity for startups who are able to accurately and securely find and ingest the context necessary for a coding task.
Currently, there are two approaches to doing this:
- Continuous Fine-Tuning: I’ve heard customers tell me ‘I wish a company could fine-tune their model securely on my codebase’. While tuning a model to your own code base might make sense in theory, in reality there is a catch: once you tune the model it becomes static unless you are doing continuous pre-training (which is costly, and could have the effect of perpetuating existing biases). Without that, it might do really well for a limited time, but it’s not actually learning as the codebase evolves. That said, fine-tuning is getting easier, so it’s possible fine-tuning a model on your codebase at a regular cadence could be viable – and for example, Codeium states they do in fact offer ‘customer-specific finetuning’ but they clearly say it should be used sparingly as the best approach is Context-Aware RAG.
- Context Aware RAG: RAG is perhaps the best available method today to improve context by retrieving relevant snippets of the codebase. The challenge here is that the ranking problem in retrieval in very large codebases is nontrivial. Concepts like Agentic RAG and RAG fine-tuning are gaining popularity and could be strong approaches to better utilize context. Codeium, for example, shared in a blog post how they use textbook RAG augmented with more complex retrieval logic, crawling imports and directory structures, and taking user intent (past files you’ve opened etc) as context. Being able to use this granular detail in retrieval can be a significant moat for startups.
Open Question 2: How do we get AI agents to work better for E2E coding tasks?
While we still have a way to go to fully functioning AI engineers, a handful of companies and projects like Cognition, Factory, and Codegen, SWE-Agent, OpenDevin and AutoCodeRover are making meaningful progress.
SWEBench*** evaluations have revealed most base models can only fix 4% of issues, SWE-Agent can achieve 12%, Cognition reportedly 14%, OpenDevin up to 21%. An interesting idea (reiterated by Andrej Karpathy here) is around the concept of flow-engineering, which goes past single-prompt or chain-of-thought prompt, and focuses on iterative generation and testing of code. It’s true that prompting can be a great way to increase performance without needing to train a model, although it’s unclear how much of a moat that is for a company in the long run.
**Note that there are some limitations to this form of measurement: for context, SWE-bench consists of Github pairings of Issue and Pull requests so when a model is tested on it, they’re given a small subset of the code repo (a sort of hint that also introduces bias) rather than being given whole repo and told to figure it out. Still, I believe SWE-Bench is a good benchmark to start understanding these agents at this point in time.
Code planning is going to take a central role in AI agents, and I would be excited to see more companies focused on generating code specs that can help an agent build an objective, plan the feature, and define its implementation and architecture. Multi-step agentic reasoning is still broadly unsolved, and is rumored to be a strong area of focus for OpenAI’s next model. In fact, some (like Jim Fan in this post) would argue that actually the moat in AI coding agent doesn’t stem from the ‘wrapper’ at all, but the LLM itself and its ability to “solve real-world software engineering problems, with human-level tool access…search StackOverflow, read documentations, self-reflect, self-correct, and carry out long-term consistent plans”.
This brings us to our last – and possibly largest – open question.
Open Question 3: Does owning the model and model infra lead to a long term differentiated product?
The billion dollar question is whether a startup should rely on existing models (whether that be directly calling a GPT / Claude model or fine-tuning a base model), or going through the capital-intensive process of building their own code-specific model – i.e. pre training a model specifically for code, with high quality coding data. We empirically do not know whether a code-specific model will have better outcomes than the next suite of large language models.
This question comes down to a few basic unknowns:
- Can a smaller code model outperform a much larger base model?
- To what degree does a model need to be pre-trained on code data to see meaningful improvement?
- Is there enough available high quality code data to train on?
- Does large-scale reasoning of the base model trump all?
The hypothesis from Poolside, Magic, and Augment is that owning the underlying model and training it on code can significantly determine code generation quality. This potential advantage makes sense considering the competition: from my understanding, GitHub Copilot doesn’t have a model trained fully by scratch, instead runs on a smaller and heavily code fine-tuned GPT model. My guess is these companies aren’t going to try to build a foundation-sized model, but a smaller and more specialized model. Based on conversations I have with people working in this emerging area, my takeaway is that we still just don’t know what scale of an improvement this approach will have until results are released.
A counter argument to the code-model approach comes from the fact that existing successful coding copilots like Cursor and Devin are known to be built on top of GPT models, not code-specific models. And DBRX Instruct reportedly outperformed the code-specific-trained CodeLLaMA-70B. If training with coding data helps with reasoning, then the frontier models will surely include code execution feedback in future models, thus making them more apt for codegen. In parallel, large models trained primarily on language could feasibly have enough contextual information that their reasoning ability trumps the need for code data – after all, that’s how humans work.
The key question here is whether the rate of improvement of the base models is larger than the performance increase from a code-specific model over time. I think it’s possible that most copilot companies will start taking frontier models and fine-tuning on their own data – for example take a Llama3-8b and do RL from code execution feedback on top of that – this allows a company to benefit from the development in base models whilst biasing the model towards code performance in a very efficient way.
Conclusion
Building AI tools for code generation and engineering workflows is one of the most exciting and worthy undertakings we see today. The ability to enhance and eventually fully automate engineering work unlocks a market much larger than just what we’ve historically seen in developer tooling. While there are technical obstacles that need to be surmounted, the upside in this market is uncapped.
We are actively looking to partner with founders experimenting with all three of these approaches, and we think the field is large enough to allow for many companies to develop specialist approaches to agents, copilots, and models.
If you are a founder working on any of these concepts (or even just thinking about it), please get in touch with me at corinne@greylock.com. If you have any additions or suggestions to the blog post, please reach out.
This post wouldn’t have been possible without the thought partnership of (in alphabetical order) Ankit Mathur, Gwen Umbach, Itamar Friedman, Jamie Cuffe, Jerry Chen, Luis Legro Correa, Matan Grinberg, Michele Catasta, Prem Nair, Vaibhav Tulsyan.