
When Tuhin Srivastava walked into the Greylock offices at 8:00 am in late 2019, he was only a few months into unemployment post-acquisition of his startup.
 Listen to this article >
Listen to this article >
He declared, without any preamble, “I’m thinking about starting a new company in ML. We just really need to take the whole pipeline cost down, and improve the iteration cycle. Otherwise, most teams are never going to ship.”
I had known Tuhin for several years, having met him and Phil Howes early in his prior startup journey and loving their talent, entrepreneurialism, user centricity and product sense. Ever since, I’d been looking for an opportunity to work with them. As it turned out, this was the moment I had been waiting for.
We proceeded to talk for several hours about the idea that became Baseten. I found the diagram from my first meeting notes, which I’ve now seen Tuhin recreate some form of many times over the past two years.
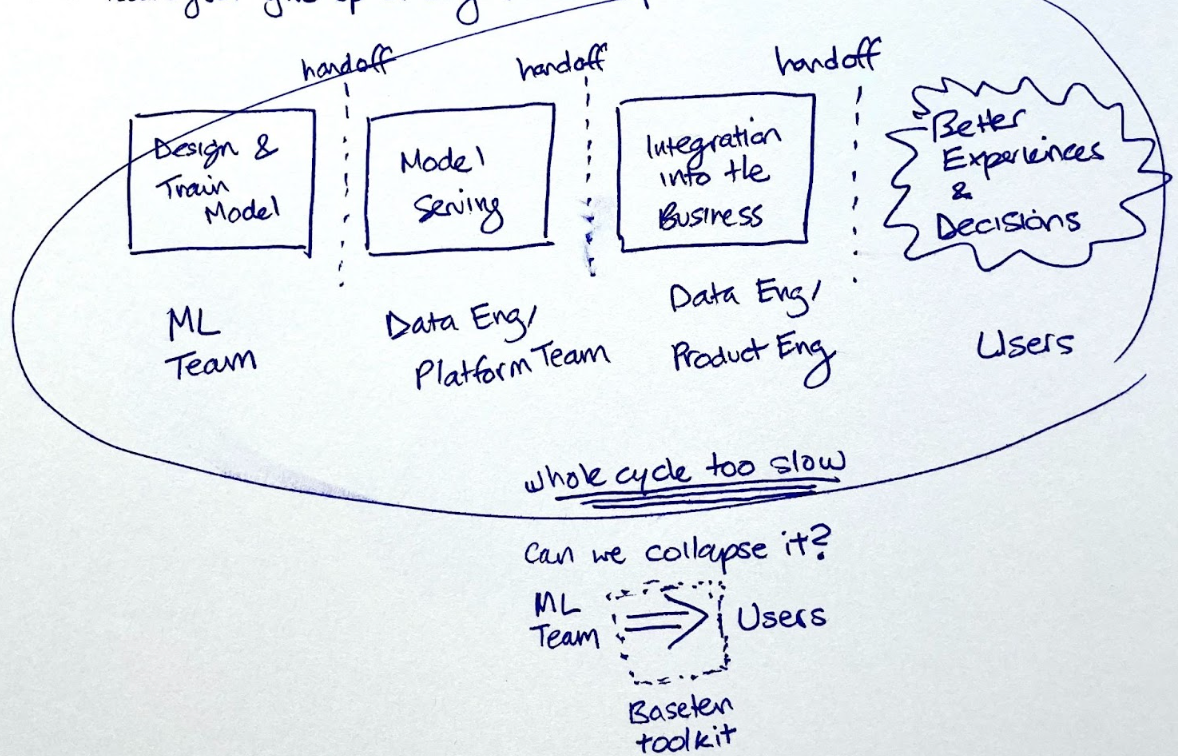
The Challenge of Unlocking ML’s Value
We are at an extraordinary point of time in the arc of machine learning. Increased sophistication in collecting and managing data, advancements in model architectures (giant transformers!), open-source pre-trained model availability, and ever larger and cheaper compute all seem to come together to promise tremendous value for enterprises – and potentially even an economy of abundance. McKinsey famously estimated that industries could unlock $5T+ of value from integrating ML. And yet, real progress has fallen short.
We constantly hear from technical and business leaders that despite significant investments in AI, they are nowhere near reaching that promised land. They describe a fatigue that has begun to set in, believing AI to be the domain of a few elite companies. We hear the frustrations from individual contributors that their models become shelfware.
Moving from Research to Impact
Baseten’s co-founders Tuhin Srivastava (CEO), Amir Haghighat (CTO) and Philip Howes (Chief Scientist) started the company based on their collective, first hand experience. At pioneering creator marketplace Gumroad, Tuhin and Phil were data scientists who had scrappily become full-stack engineers so they could use ML to defend against fraud and abuse, and moderate user-generated content. At Clover Health, Amir had led teams that developed ML models to drive population health management.
In talking to their friends at companies of differing scales and verticals, they realized the pain they faced was widespread.
Operationalizing ML requires high coordination, highly skilled engineering and product work beyond data science. Today, once they have trained a model, data science teams need to coordinate with data teams to implement data pre and post-processing. They need to work with devops and backend engineers to deploy and serve the model as an API (with the output usually being a prediction, classification, or generation of some content). From here, companies need to integrate that API into existing systems and processes, or invest front-end development and design resources to build new interfaces for end users, as well equip the end users with sufficient context to interpret and accept or reject the ML predictions. They need to stitch all of this together, scale it and monitor it.
This is a gargantuan task, and today only the most motivated and well-resourced teams succeed. Even then, they only manage to ship their highest-priority use cases.
Under the status quo, even “simple” models can take 6+ months to ship. Many projects run behind schedule as stakeholders struggle to align and investments are withdrawn or resources reallocated. When teams persevere to deliver to the end user, they often realize there was an understanding gap between the supposed spec, and what business users actually needed. Often, after all this engineering effort, teams find out they need to collect more data or change their labeling. Without iteratively incorporating feedback, context around the data, and domain knowledge from business users, the model builders risk constructing models that perform sub-optimally and do not become integrated into business decision-making.
In response, the Baseten founders envisioned a unified platform for data science teams to build full-stack custom ML applications in hours instead of months. We signed up for that vision, co-led their seed with South Park Commons and dove in. The team built and iterated towards a v1, having hundreds of conversations with end users and buyers along the way. They also recruited an exceptional early team, hailing from GitHub, Google, Uber, Amazon, Palantir, Atlassian, Confluent, Yelp, AirTable, and more.
Software for Shipping (ML-enabled) Software
Baseten isn’t “no-code,” it’s efficient code. It is a powerful software toolkit that empowers technical data science teams to serve, integrate, design, and ship their custom ML models efficiently. They can write arbitrary code wherever they need to, and not where they don’t. It speaks their language (python) and tools (jupyter notebooks), and it unblocks ML efforts that today are bottlenecked on infrastructure, backend and frontend engineering and design resources. It collapses the innovation cycle for ML apps, making cheaper experimentation and therefore more success possible. Under the hood, it’s powered by a scalable serverless platform, and designed for public or private cloud deployment. Baseten is modular, and we’re excited to already be receiving strong community interest in contributing to an ecosystem of models, components and integrations that allows for greater leverage for every ML team.
- With Baseten, users can:
Create interactive model evaluation apps, demos, prototypes — build web apps to show off the power of machine learning models and get feedback from stakeholders and users to close the feedback loop sooner, or extend the visibility of new research - Build tools for machine learning — create custom tools that help you train more models and make your existing models better (e.g. model output and data browsers, labeling interfaces, model monitoring workflows)
- Build production-grade, stateful, workflow-integrated ML apps — e.g. integrate fraud models into complex financial decisioning, or use a classifier like toxic-bert from the Baseten “model zoo” to power a content moderation queue
Investing in Baseten
Jason Risch and I are thrilled to be leading the Series A investment for Greylock, and I am joining the board.
Working closely together with the team, we saw strong demand for the product from both commercial teams and the research community, and success with early adopters such as Pipe, Patreon and Primer. Our conviction as investors only deepened. We are excited to team up with an exceptional set of coinvestors across AI, developer platforms, design and community, including Lachy Groom, Ray Tonsing (Caffeinated Capital), Andrew Ng (AI Fund), and angels including Greg Brockman, Dylan Field, Mustafa Suleyman, DJ Patil, Dev Ittycheria, Jay Simons, Jean-Denis Greze, and Cristina Cordova.
I recently sat down with Tuhin on the Greymatter podcast. You can listen to our conversation at the link below, on YouTube, or wherever you get your podcasts. And read more from Tuhin and the team here.
Sign up for the free open beta – or if you want to build software that helps more ML make it into the real world, we’re hiring!
Episode Transcript
Sarah Guo:
Hi, everyone. Welcome back to Greymatter. I’m Sarah Guo.
It remains very difficult to build end-to-end products that leverage machine learning for business impact. Baseten makes it fast, seamless, and serverless to build scalable, user-facing workflow integrated apps powered by AI.
We’ve been working with the Baseten team since inception and are so excited to announce the company’s 20 million seed and series A financing today led by Greylock and open availability of the Baseten platform. I’m here with Tuhen, co-founder and CEO of Baseten. Welcome, Tuhen.
Tuhin Srivastava:
Thanks, Sarah. Nice to be here.
SG:
Can you just start by telling us what the Baseten platform does?
TS:
Yeah, absolutely. Baseten reduces time-to-value of machine learning efforts in businesses. We enable teams to incorporate the machine learning models into production- grade applications within hours instead of months.
With Baseten data science, the ML teams can easily pre-process data, serve their models and build UI. So you can end up with a standalone machine learning application or within a single end-to-end platform.
SG:
That sounds like a lot of the functionality in the machine learning tooling and applied ML space – a space that has a ton of startups and existing tools. Where does Baseten sit amongst all that? Being aware of the landscape, what convinced you that there was something important that was still to be built here?
TS:
Yeah, absolutely. So, I think it’s worth just stepping back and thinking about everything that goes into shipping a machine learning model from, “I have a problem” to, “I have something that’s integrated into this, and adding value to it with machine learning.”
So, you obviously make a problem statement, but then you prepare your data, you train your model and that’s what data sciences are traditionally been very, very good at. After that you need to somehow get it posted somewhere. And that’s where tools like SageMaker come in. In the past, people have used stuff like Flask and past API. Some data scientists can do this, but it starts to get pretty hairy really quickly, especially when you start dealing with a lot of infrastructure or you need to think about high performance applications, but that’s really just a model behind an API.
Once you have that, you need to start to actually integrate the business logic. So that might be pulling the data from somewhere, doing some transformations, writing it back to some other third party service or integrating it with a system of record. And then, if it’s a workflow application, you oftentimes need to go to UI. And so there’s a ton that goes in from zero to value in building with machine learning.
Yes, we deal with the machine learning ops things, but we’re much, much more focused on going from model to business value as opposed to model to behind an API.
And so the question you asked was like, how do we think there was something, especially in such a noisy landscape? Why was this something worth building us? It’s because we saw white space and this idea of productizing models is going from trying to think of machine learning as a product function, as opposed to a research function and what would be the tool that unlocks that.
SG:
Yeah. I do think that there’s a really odd dynamic in the machine learning landscape overall, where the research functions of a very small number of largely private companies, less so even academic institutions these days have made these amazing contributions in model architecture and new techniques to the world. And a lot of that has ended up in open source, but the realm of actually applying any of that innovation to real business problems is massively underserved. And not really focused on by much of the industry versus for example, like hitting a new benchmark or an improvement in model architecture.
Our assessment of the space at Greylock is that the vast majority of companies, even those with significant machine learning investments in data science teams and their own product engineering teams were very, very early that journey of the application, much less having their own research effort.
And so I definitely saw eye to eye with you guys on that. I also think that if you ask people today and I ask the portfolio companies that we get to work with, to talk about their machine learning strategy, not always, but very often it ends up being a second step in their company strategy, which is, oh, when we can afford a team of a bunch of data scientists and we can really resource this, then we’ll invest in it.
I’d love for you to talk a little bit about your background and the experience that you guys have had with Gumroad and with other companies you’ve worked for.
TS:
Yeah, absolutely.
I have two co-founders, Phil and Amir. Phil and I actually grew up together in Australia. We’ve known each other since 2012. And we met Amir in 2012 when we were amongst the first few employees at the company called Gumroad, which is a creative marketplace. And we were tasked with this problem.
We were a really small team. We were getting smashed by fraud. There was more fraud than there was the actual volume for a while on the platform. And then people were uploading all sorts of weird content and we’re like, “oh, this seems like a pretty machine learning problem.” And out of the data set, someone with a machine learning background, right. I was like, okay, yeah, I can get a model up and running to do these things quite as the end.
Prior to Gumroad, I actually worked at a research lab in Boston where we were using machine learning to predict the diagnosis and prognosis of neuromuscular disease. And this largely in our academic exercise, we’re publishing papers more than we’re actually building value, but I didn’t really have that engineering skill set.
So we, lo and behold, I spent a few weeks putting together this data set, came up with a great model. And I went to Amir, who at the time was the de facto CTO, and I was like, “Hey, can I have some resources?” And they were like, “What does that mean?”
I basically realized that I had to learn to become a full stack engineer to actually get a new value on my machine learning model. So I went and I knew Python, but I didn’t know anything about service. So I learned how to build a FLAS gap. I deployed it to AWS. It took me way too long. And then I was like, Okay, cool. Now I have my model behind an API.
I was like, “Now can I have some front end engineering resources?
And they were like, “There’s no retail at the time.” And I was like, okay, “Well, I’m probably an engineer now.”
And so, within a couple, within a few months that I used to get value from this model, I had to become a full stack engineer. And I quickly realized that while there was a lot of work that goes into preparing data and training a model – and I didn’t want to scout that work – there’s just as much work, if not more, that goes into actually connecting that model to actual business value.
And for me, this was great. I wanted to be a founder and I got to learn to be a full stack engineer on the job. So I could build whatever I wanted in the future.
But if you think about it from a value proposition perspective, to go, “I’m ready,” and “Great, it took out a person,” – it was really clear that for every model we came up with, we’d have to pair it with in equivalent amount of engineering resources to make it work.
I think right after that, me and Phil actually started another company called Shape that was acquired in 2018. Amir went to work at a company called Clover Health where he was managing a data platform. And he was told the same thing. At Clover Health, they were trying to provide smart diagnosis at the point of care from two doctors. So they were taking medical records, they’d mine it, they’d take control of the plan and be like, “Hey, you should check XYZ.”
Again, the data scientists come up with a great model and they’re like, “Okay, so how do we actually get this in front of doctors?”
Obviously, they didn’t have the resources. We’re all constrained for engineers. And they came up with this great idea: they put it in a spreadsheet and the doctor would look it up; it was the output on the table. And obviously the barrier here, for that workflow, was that in this case, the knowledge worker was actually the doctor. To actually do that work, to be able to interact with the model was way too much. There was no ROI seen and those efforts were scrapped.
And so it became really clear to us that data scientists weren’t equipped and machine learning teams weren’t equipped with the skillset themselves, to be able to ship these full stack solutions, and they did not often have the resources internally. As a result, teams were coming up with a problem that was clearly solvable by machine learning. They were coming up with the initial model, but not being able to show value. And so, as a result, other stakeholders (management) would lose faith, so as a result those efforts would get nixed.
To us, it seems like if we can reduce the barrier to these companies that clearly have a business critical way to use machine learning, we think that’s the future that we’re going in. [We think] that all these tasks today, where humans are making decisions, need augmentation, and then automation will come with tools like Baseten.
SG:
Yeah. The story of both these engineering learning curves that you went up yourself, and then the stymied efforts of Amir and his team at Clover health, I’m sure also mirror a lot of the conversations you had with data scientists as you were exploring this idea.
But it’s clearly not what any of the companies that are recruiting these machine learning tools are out to do, right? The likelihood that any of them is going to recruit high-quality machine learning people (who are also going to learn backend and front end engineering and DevOps, and string together a service that way, single handedly) just feels low, or it feels like an impossible ask if what we’re aiming for is the democratization of ML.
TS:
Yeah. And nor should they, right? In the sense that, it is the best use of a very, very, very smart PhD from Stanford to go and learn how to make React apps. I don’t think so.
SG:
Yeah. So let’s talk a little bit about how when you went through this, who did you end up deciding to build Baseten for? Who’s using it today now?
TS:
Yeah, absolutely. So I think, we were ourselves like ICs or telecom ads: startups that were going through some growth and didn’t necessarily have the resources to build that infrastructure to have all that infrastructure in place so we wouldn’t have to go to ourselves. Turns out that we think that’s 90% of the market right now, when it comes to machine learning teams.
And so I think, when we think about who we target, it’s exactly these hospital-type of machine learning and data science teams that really have the expertise to train a model, but don’t have the support.
And what we’ve seen is that when you give access to these IECs in this bottoms-up way that we’ve started to target in the last year, all sorts of weird examples come up.
And it’s really cool, whether it’s at the larger scale – we have teams like Patreon and Pipe who are using it for content moderation, underwriting assets, and they’ve also started using it for data labeling and transcribing audio. What we saw with those larger companies was that once you gave folks access to something that unblocked them, they got the imagination going to what else they could do. And as a result of Baseten, there was actually more machine learning at these companies.
On the other side of the spectrum, we’ve seen the really, really small chain of startups or nonprofits with it might not necessarily have the resources to operationalize these models.
People are just using Baseten for all sorts of use cases, like for user verification. One of my favorite examples is this company called Primer where they’re using it to detect if someone is an adult or a child in these audio rooms (where children can talk to each other).
We have nonprofits using it for translating language models. They are translating COVID materials and putting them on the ground in Africa. We have a climate company using it in Europe to figure out where to place energy grids offshore.
And so, to me, what was really amazing is that by targeting the IECs, we’ve unlocked all these different use cases that we didn’t think about.
SG:
I know you guys are focused on being an applied company versus primarily a research company, but that still sounds like a researcher’s dream to be seeing how people are using all these different data sets that you often don’t really have access to in academia versus, I don’t know, for example, ad performance data on media. I love hearing about the different use cases.
So you mentioned you’ve been working on Baseten for over two years now and you brought people onto the alpha release just about a year ago. Who were some of the early adopters to help develop the product and figure out what to focus on?
TS:
We experimented early on with all sorts of people. One of my earliest customers was a large FinTech company trying to build their fraud underwriting system with Baseten. They didn’t have the resources to build internally. We did some cycles with a large airline where they were trying to build departure delays models. And we also did early iterations with a bunch of just ICs who were building prototypes.
I think, for us, what was key there was that we wanted to be a horizontal company and we still aspire to be. We’re not wired to any one use case of Baseten. If anything, this is the ethos of our company we have carried forward: empower creatives with tools and to see what they’ll do. And so we cast the net really wide.
But one thing we noticed really, really quickly with all these users was that data scientists and machine learning teams, they know Python, but they’re actually more product thinkers than you’d think. They think in terms of customer problems as opposed to engineering problems, and they don’t like infrastructure.
Going back to that customer journey, what is going to be the tool that allows them to think in terms of the customer’s needs? How do we allow them not to have to worry about infrastructure? And how do we utilize what we know [that] data scientists and machine learning teams know really well, which is Python. And I think that’s really what led us to building what is Baseten today; this understanding of, Let’s lean into the technical persona, let’s make sure that we are optimizing for what they want to do, Which is solving problems and make sure they don’t have to do anything that they hate doing.
SG:
How did you think about maturity and scope as you built this out? And can you talk a little bit about the iterations and journey to get here?
TS:
Yeah, for sure. I think that actually goes just beyond just daytime machine learning. I think today the general developers’ expectations of product quality is higher than ever. I mean, and that’s amazing for the developer. It makes it really daunting when you’re starting to build a horizontal product around all the things you need to build.
And I think, one thing that we were really focused on was, we wanted the product to be strong enough that it can deliver value, but usable enough that value could be self-obtained by the data science and machine learning team, and that we didn’t want to do a bunch of hand holding.
We’ve gone through so many iterations of Baseten. We built our first version of the product and we were targeting the enterprise for a bit. So we didn’t really focus on usability at all. We got abstractions wrong along the way.
One of the things that we wanted to ensure that we had were these abstractions that made the easy things really easy. You have to think about data and your YAML files, but when you want to add a GPU to your model, that should be really, really easy. And what this meant was that we had to have these abstractions that supported this wide array of easiness, but also allowed customers to build on top of us.
And so, the first version of our backend was wrong and we rebuilt it (the first, we’re about to release very, very soon). And I think customers really struggled with going from zero to one. But we were able to use that time to prove that value by helping customers. But we did have to rewrite big parts of the product multiple times over and over again, to ensure that it was usable. And I think this is going to be a work in progress, and it’s going to be a journey that we’re on. I think the product’s in a really good spot, but we’re nowhere near where we want to be.
SG:
Was there a specific user story or experience that someone had with the product that made you feel like, “Hey, we finally are on the golden path,” ? I know you and the team have been incredibly excited about the cumulative efforts of grinding away on usability over the last months.
TS:
Yeah.Some time in the last month or so, we realized that people were building stuff without us knowing, and that was a really big step for us in the sense that people were getting into the product. We’d onboarded them months ago, we thought they turned off, and they came back and we have this group of crypto developers who are running a consultancy on Baseten (and we don’t talk to them). And all of a sudden, one day they built all this UI, and the big moment for us was when they started talking in our terms: We have these concepts of views, backend endpoint, which we call workloads and model deployments. When a user calls you up and starts telling you about, “Hey, this workload, it’s not working for me,” it’s this magical moment where you’re like, “I made that concept up!”
That’s been a really great moment.
SG:
Yeah. That’s really cool. And they’re learning those concepts by themselves from the product and it’s worthwhile. And so I think that is a huge unlock.
So, we had long discussions about where the value was and what type of company you wanted to build from a go-to-market perspective. And you went through a few iterations and then just very much committed to building a product that a single engineer or data scientist could self-serve. And now you’re seeing the magic of that. Why is that important to you? And if it’s one user at a time, how does an organization adopt Baseten?
TS:
Yeah. That’s a good question. I think why it’s important to us is like, we went through lots of iterations, as you said. And I think for a while, when it was just me and Amir and Phil, we just decided at some point that if we’re going to build a company in the long term, we had to be really excited about the go-to-market motion and it had to match who we were as individuals.
One of the things that I talked to other founders about early on in their journey is that, whatever you do, it’s going to be really hard. I don’t know the easy way of building a company, Sarah.
SG:
I don’t, unfortunately.
TS:
And I think there’s two things that we decided early on was that if we’re going to do it, we’re going to take a big swing. And if we’re going to do it, we may as well work with the customers that we like: people like us, that we really enjoy talking to and spending time with. And that’s been really amazing, working with engineers and data scientists. Our customers are really smart. It’s honestly a privilege that we get to spend time with it. We learn from our customers constantly, which is amazing.
How organizations are using Baseten is a really good question. What we’ve seen is that usually it’s one data sciences engineer. They get in without playing around it. What we’ve found is actually it doesn’t really matter what the use case is. It can be with or without machine learning. There are just so many applications that get built from the point of, “I have no data” or “I have data” to “I have something shipping and adding value. I want to iterate on it.” It doesn’t really matter what they come in. They come in, they start building, they build a tool, they usually start to invite either other data scientists or people who will use that tool onto Baseten.
And then what we see is that once they’re in, they say, “Well, you guys do X, Y, and Z as well.” So, [for example] Patreon started with a digital labeling tool and they were like, “Oh, but you guys do model deployment too. We should give that a shot.”
It was the same with Pipe, exactly the same journey. They started with this really lightweight digital labeling tool. And then they were like, “Oh, actually we have this model, can we deploy it?” So usually what we see is that it doesn’t matter what they come in to do, but they come in to build an application. They bring other people in and they just start to build all.
SG:
Yeah. I mean, just as somebody who invests in a lot of collaborative tooling for technical audiences, I feel like this is part of the magic of this type of business, which is incredibly hard to get right from a product value and usability and aesthetic and distribution perspective. But when you do, the amazing thing about technical people is they choose tools for much of the organization and they take the tools they like with them. And it’s amazing to see you guys empowering that.
The company has accelerated hiring dramatically over the last six, 12 months. Can you talk a little bit about where you guys are as a company, and who the team is, and how you collaborate?
TS:
Yeah, absolutely. So we are a group of 20ish people, where we have a small office in San Francisco, but we are simply a remote company. The office is more of a social gathering spot, as opposed to a place where people do work.
We didn’t set out to build a remote company, to be frank I was actually quite against it, I was like, “I love being in the office, what are you talking about?” And I live in LA and I fly out to be an SF to be around people constantly. But what we realized once the pandemic hit was that, it was actually a golden opportunity to hire all folks who otherwise wouldn’t consider working at a company like Baseten because it wasn’t a big company. And as a result of this remote culture, we have people in San Francisco, Los Angeles, Seattle, Montana, Quebec City, New York, Boston, Armenia.
And it’s been fantastic just to see the different types of talent that remote workers unlock for us in terms of what that means for us. I think we had one employee hired before the pandemic, but for every other company that’s matured during this period, it’s still a work in progress. We’re figuring it out. But we do our work, we spend a lot of time on Zoom, unfortunately, but at the same time we’re figuring out how to make that effective.
We’ve been really, really lucky to be able to hire some, really, really senior, kind, thoughtful folks who have a really constructive mindset to work. And a lot of that’s been from my network, but I can’t not give a shout out to John and Dwayne over the Greylock recruiting team, who have just been fantastic in terms of adding value. It’s pretty unreal, I think. And in this hiring climate, that is just ridiculous. And these are high-quality people who have shaped our company and we wouldn’t be where we are without them.
SG:
Well, we’re rooting for your success and John and Dwayne, if you hear this, we love you.
So, this is actually a pretty broad product, and now you have a certain level of product maturity, and you have production deployments. You’ve still decided to call the platform release a beta. Why are you doing that? And where are you excited to continue deepening and extending the platform?
TS:
Yeah. Two things: I still think we’re at the earliest stages of learning. We have a lot – the product feels mature and we have production use cases – but we’re still figuring out a lot of the usability things, and I think the reason why we want to call it beta is just to invite people into the product without having high expectations of what they’ll build, and really surprise them once they’re in.
I think it also gives us a bit more wiggle room in terms of making sure all those abstractions are right. We just have so much to build and to get the product. We hope that Baseten over time can power a lot of value – and hopefully we can capture a small amount of that value and build a really valuable company – but overall, to get there, to take a minute, we’re not there yet.
There are three parts to Baseten. It’s a pretty wide product, right? So there’s the model deployment engine. We have the workload builder, which is basically an API endpoint builder which allows you to embed a model and surround it with all sorts of codes so you can actually build business logic alongside that model. And then we have a UI builder. I think, given that we have these three pretty intense components, let’s be honest – there are three mini companies or mini products within themselves.
There’s a lot to build. And what that means is that everything is at a slightly different maturity. And one of the reasons why we’re releasing this as the beta is because we want all the three things to be up to parity before we have a go GA.
I’d say today, the workload and the model deployment piece are doing really well. We’ve seen lots of value being added there. And the UI builder is a bit earlier in its life and we’re going to continue to iterate and learn from customers. And as part of this beta, the goal is to get that up to the same level of maturity and then we’ll go GA.
So the cool thing about having these three different places, three different product pillars, is that it actually gives us three places to build this platform and ecosystem.
On the model side, you can deploy a state-of-the-art model with Baseten very quickly. Today we have, I think, maybe over 30 state-of-the-art models that you can deploy with a click. That’s a way to back the original classification (we have a GPT-3 integration). You can use these state of the art models and it gives us a way today to build the ecosystem there.
I think on the workload engine side, you can almost think of the way of assembling these business logic code blocks, and we can build an ecosystem around the different snippets of code you might surround your model with. [For example] If you’re a data scientist and you want to write your prediction back to Salesforce, do you need to write that integration yourself or can Baseten do it for you?
And I think the third part is the views, where we have these views with these individual components to drag and drop builders and we’ve already had customers ask us, “Can we contribute back to this so we can reuse some of these components?”
I think the even more exciting thing is when we take all three of these things and they’re in templates, and I think we can have an ecosystem of templates that uses a model with some workloads, with a view for a particular use case. So if you are a company with a content moderation problem, can Baseten take you zero to one or zero to 80 or 90% of the way there with this prebuilt template that uses a specific type of model, has all the curing logic and verification logic built in and then have the UI for reviewing those predictions.
SG:
Yeah. I mean, that last piece sounds the very holy grail for many machine learning applications. I think most organizations – let’s say they can find the Tuhin, and Phil and Amir unicorn hat’s like, “Yes, I personally know data science and full stack engineering, and I’m motivated to build it all together.” Given that they’re still stuck between, “I’m going to use some off the shelf application or API against my use case, or I’m going to build it all from scratch myself.”
I think what people really, in many cases, want is the ability to use a state-of-the-art model and to tune specific parts of that workflow. And that could be, as you mentioned, pre-processing, or it could be the UI for the analyst in a fraud use case, but not take the entire lift of building that application from scratch and get all of the performance and benefit.
TS:
Yeah, totally.
SG:
The glorious future, it’s coming.
TS:
I hope so. And then in terms of just with all three of those pieces, we do think about them in a modular format, so you don’t have to use all of Baseten to get value from it. You can use just the model deployment piece builder or the workload builder, or just the view builder, and we’re built for you to integrate in and out of Baseten across those three pillars.
SG:
You’ve talked about Baseten being a very mission-oriented company. If Baseten succeeds, what change do you hope to see in the world in the next decade?
TS:
Yeah, absolutely. I think, if we’re successful, we’re going to reduce the costs of shipping ML. Iteration cycles will be quicker. More people will be collaborating around models. And I think overall, if there’s anything you can do to increase collaboration and quicker iteration cycle, you’ll see an effectiveness in the overall process. And that’s really what we hope is that, as a result of Baseten, we are going to increase the effectiveness and machine learning efforts.
And as a result of that, really, is going to result in more models, more businesses, because there’ll be more investment because we are seeing how ML is moving the needle for real organizations.
SG:
Yeah. I absolutely believe that.
Tuhin, thank you so much for doing this. Congrats to you and the entire Baseten team on the platform launch. We’re thrilled to be working with you.
TS:
Awesome. Thanks, Sarah.