
Voice has emerged as a widely adopted modality in applied AI.
From call centers to scheduling assistants, voice agents are entering more production use cases across various industries than ever before. Despite how natural it feels to speak, building low-latency, conversational voice agents remains deceptively difficult.
In this post, we explore how teams are bringing voice agents into production across three distinct layers of the stack: core infrastructure, frameworks and developer platforms, and end-to-end applications. Then, we break down the core technical challenges of building voice agents and also highlight where we see enduring infrastructure needs across the voice stack.
At Greylock, we make a deliberate effort to understand the technical architecture of building voice agents in order to better empathize with the engineering complexity and more effectively assess product depth and technical differentiation in the space.
Three Layers of the Voice Stack
Teams deploying voice agents in production typically operate across one of three layers of the voice stack. Each comes with its own engineering tradeoffs and product considerations:
- Core Infrastructure
Teams operating at this layer design, build, and deploy their own voice architecture end-to-end, which involves managing a range of infrastructure beyond just model orchestration. They must account for components such as cross-platform audio SDKs, real-time monitoring, and deployment across edge environments. They also often build in support for retrieval-augmented generation (RAG), external system integrations, and application-specific logic. While this approach requires deeper infrastructure and voice expertise, it offers the highest level of flexibility and control. - Frameworks & Developer Platforms
Platforms like Vapi and Retell provide frameworks that reduce the lift required to build custom agents, offering function calling, prompt chaining, and webhook support out of the box. They’re typically favored by teams who do not want to invest engineering resources into building all the required technical infrastructure from scratch but still want fast implementation with flexible, configurable infrastructure primitives. - End-to-End Applications
Companies in this layer typically build their own core infrastructure to deliver full-service voice agents where they abstract the technical complexity away from end customers across segments such as customer support, healthcare, and home services. Teams like Netic, Cresta, Bland, and Simple collaborate closely with end-users on implementation, often wiring in knowledge bases, APIs, and business logic. This is where workflow integration and a strong GTM motion matter most.
Each of these approaches represents a different trade-off between speed, flexibility, integration overhead, and engineering investment.
Voice Agents Under the Hood
Today, most production-grade voice systems generally follow a three-part architecture: (1) a speech-to-text (STT) model, (2) a large language model (LLM), and (3) a text-to-speech (TTS) model. Most STT–LLM–TTS architectures incorporate a Voice Activity Detection (VAD) layer to detect when a user starts and finishes speaking. VAD typically runs before or alongside the STT model to gate when audio is transcribed, reducing unnecessary computation and latency. In systems like Deepgram, VAD is integrated directly into the STT pipeline, emitting events during streaming to signal speech start, end, or turn completion. Some architectures also implement post‑STT turn detection, where a transformer‑based semantic model analyzes the transcription to decide whether the user’s turn is over [article].
An emerging alternative is using end-to-end speech-to-speech (S2S) models, which would skip the intermediate transformations from audio to text and then back to audio. These models are generally more expressive and conversational out-of-the-box. While compelling, S2S systems are not yet ready for most production use cases due to increased likelihood of hallucinations and limitations in function calling, slower inference times, and less powerful reasoning ability.
Whether using STT–LLM–TTS or S2S architectures, the underlying challenges remain complex. Delivering high-quality, real-time voice interaction requires solving problems across the entire stack. We list a few technical considerations below and highlight areas of the architecture that are most relevant:
Latency
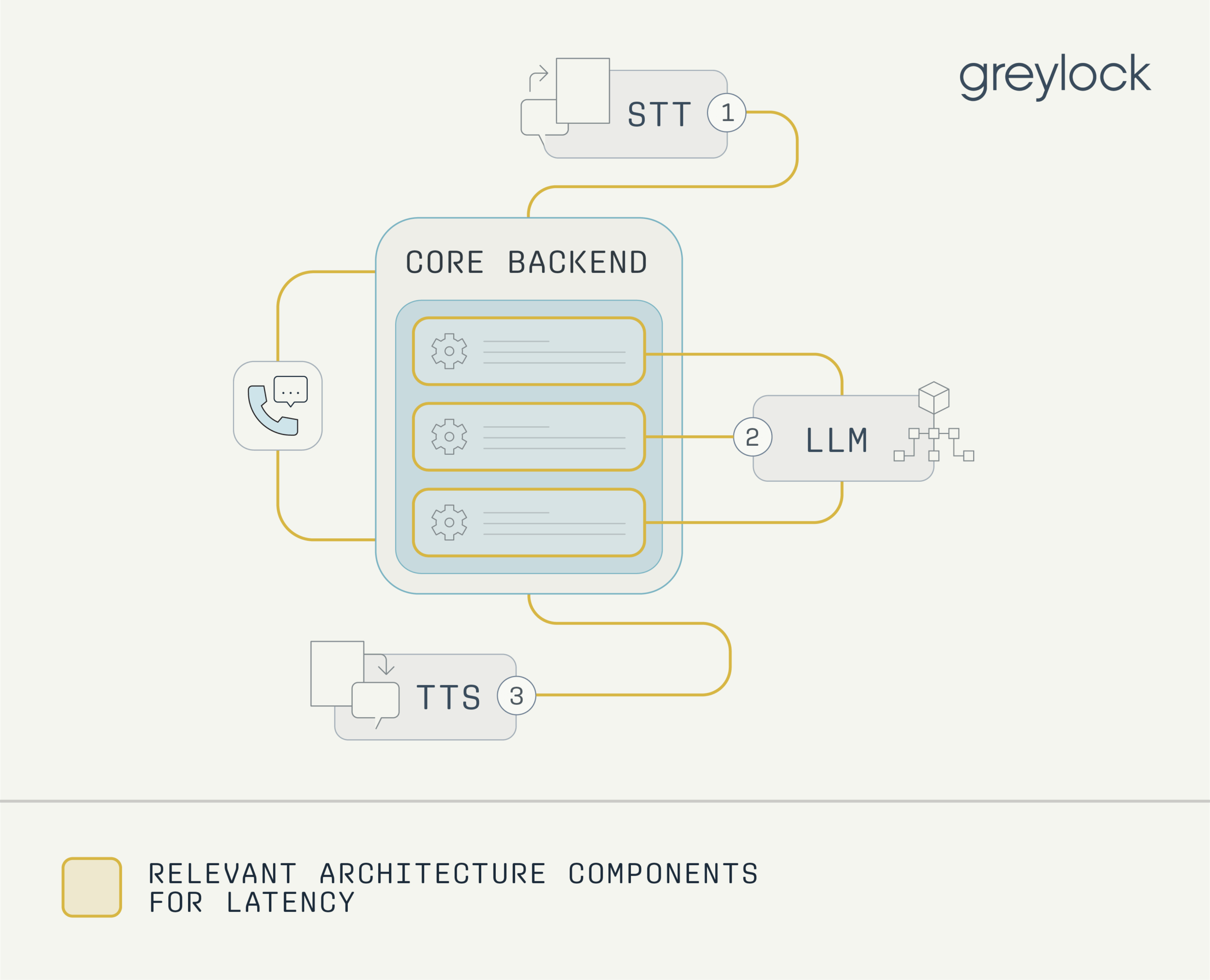
Meeting real-time latency goals in voice systems is a multi-layered challenge. Before any backend processing occurs, protocols like WebRTC which is the standard for low-latency audio transport, typically introduce around 250 milliseconds of latency in each direction. This creates a baseline of roughly 500 milliseconds of latency, even under ideal conditions. On the backend, STT, LLM, and TTS models are typically called in sequence, often alongside function calls that may involve additional network requests. Each step adds latency, making it difficult to stay within the commonly accepted threshold of 700 milliseconds for real-time voice interactions.
To reduce end-to-end response time, some systems use speculative techniques, such as sending the LLM request before the end-of-turn detector has reached full confidence that the user has finished speaking. While this can result in redundant inference calls, it can significantly improve average latency. These design choices reflect the ongoing trade-offs between speed, cost, and interaction quality in production-grade voice agents.
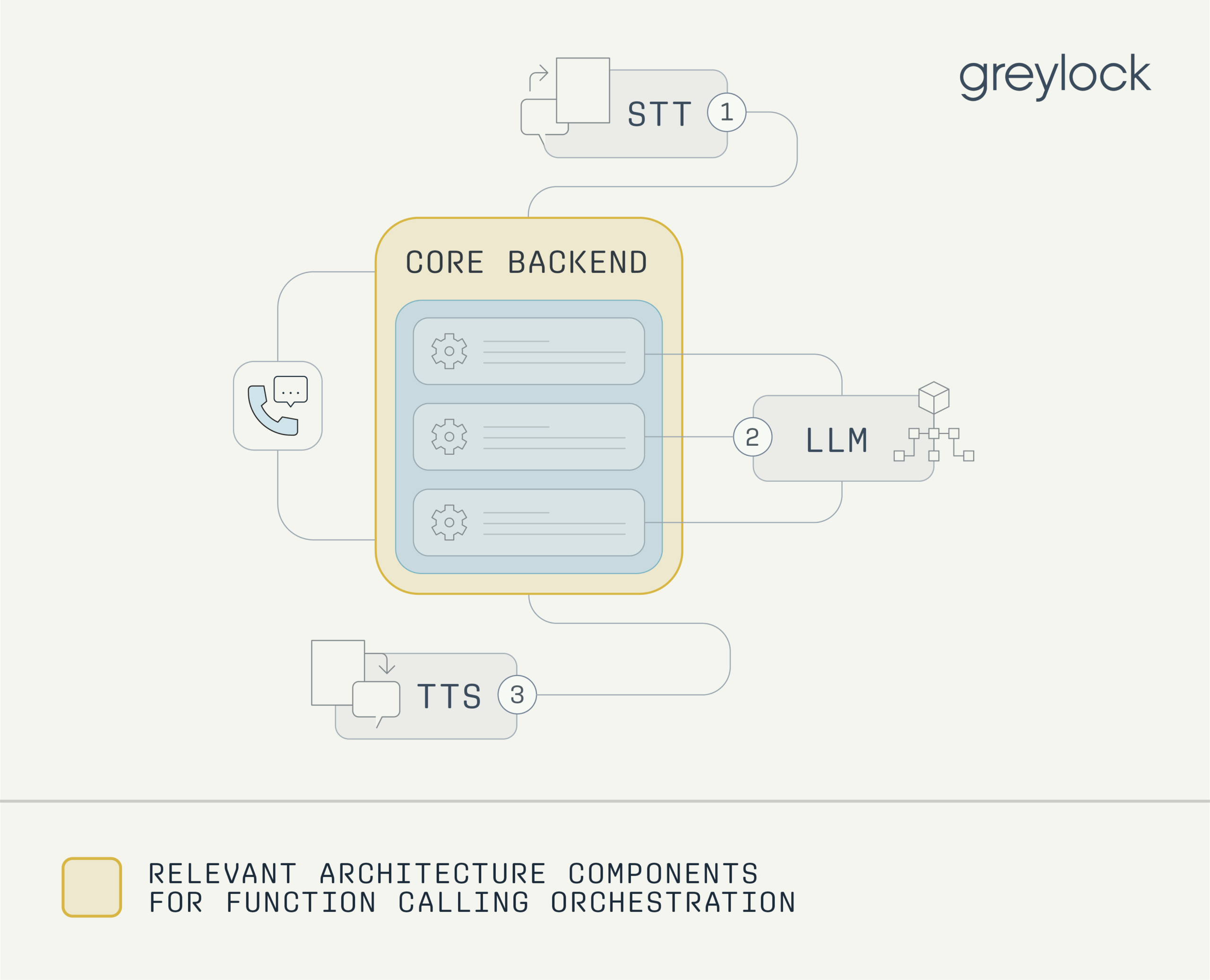
Function Calling Orchestration
Function calling allows models to fetch data and take actions. Given a list of functions and business logic context, voice agents must not only decide which function to invoke, but in what sequence, with what parameters, and when to pause for user input—often under tight latency constraints and in non-deterministic environments. These function calls can include decisioning to make call transfers, escalations to human agents, data lookups, multi-step tasks, and complex branching workflows.
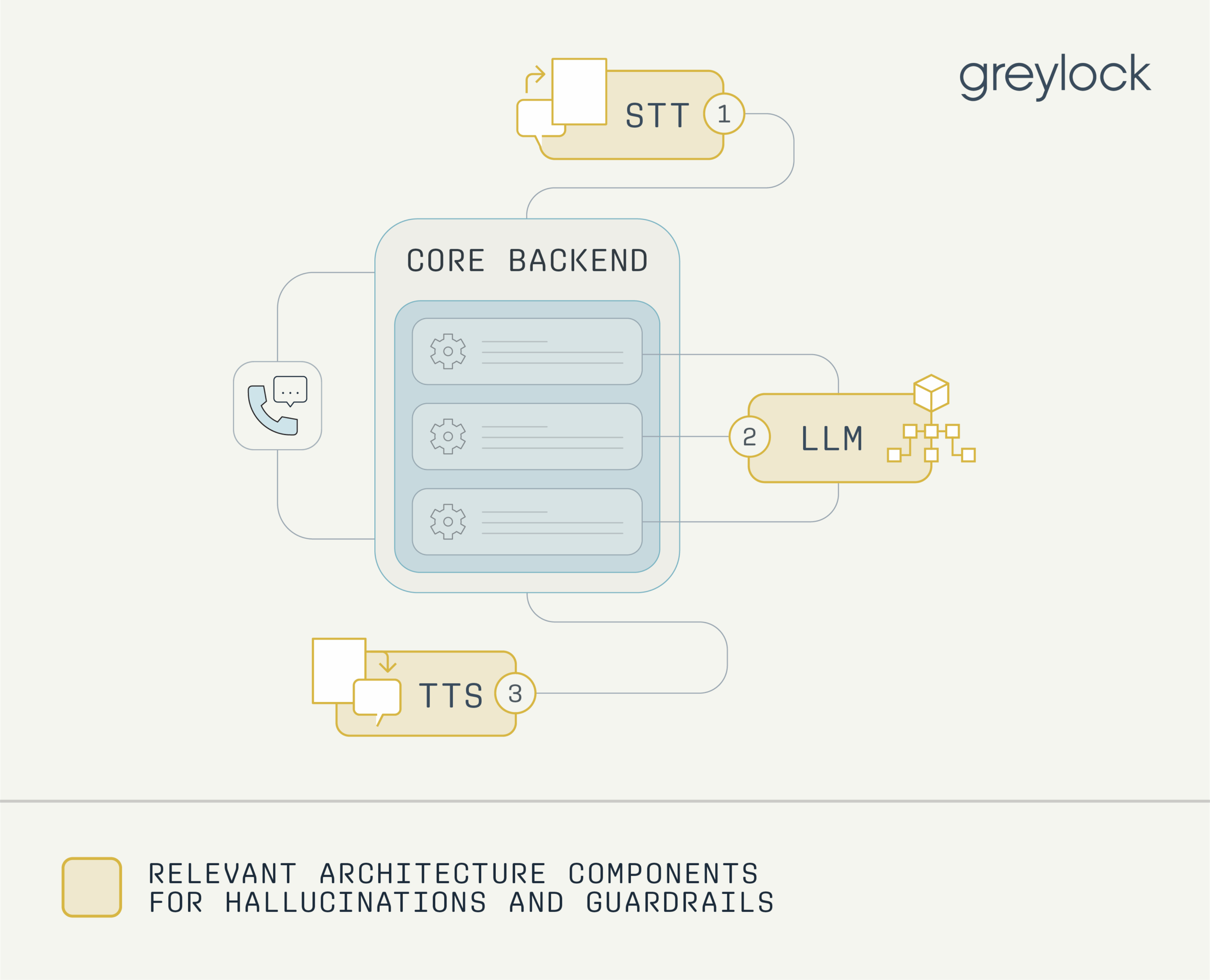
Hallucinations and Guardrails
Avoiding hallucinations in high-stakes or regulated domains is essential, particularly when voice agents handle sensitive workflows in healthcare, finance, and other highly-regulated industries. Guardrails are critical to keep responses grounded, safe, and contextually appropriate. This applies not only to conversational hallucinations—such as incorrect facts, misleading reasoning, or unsafe responses—but also to voice-specific errors like mispronunciations, inappropriate tone, or altered speech.
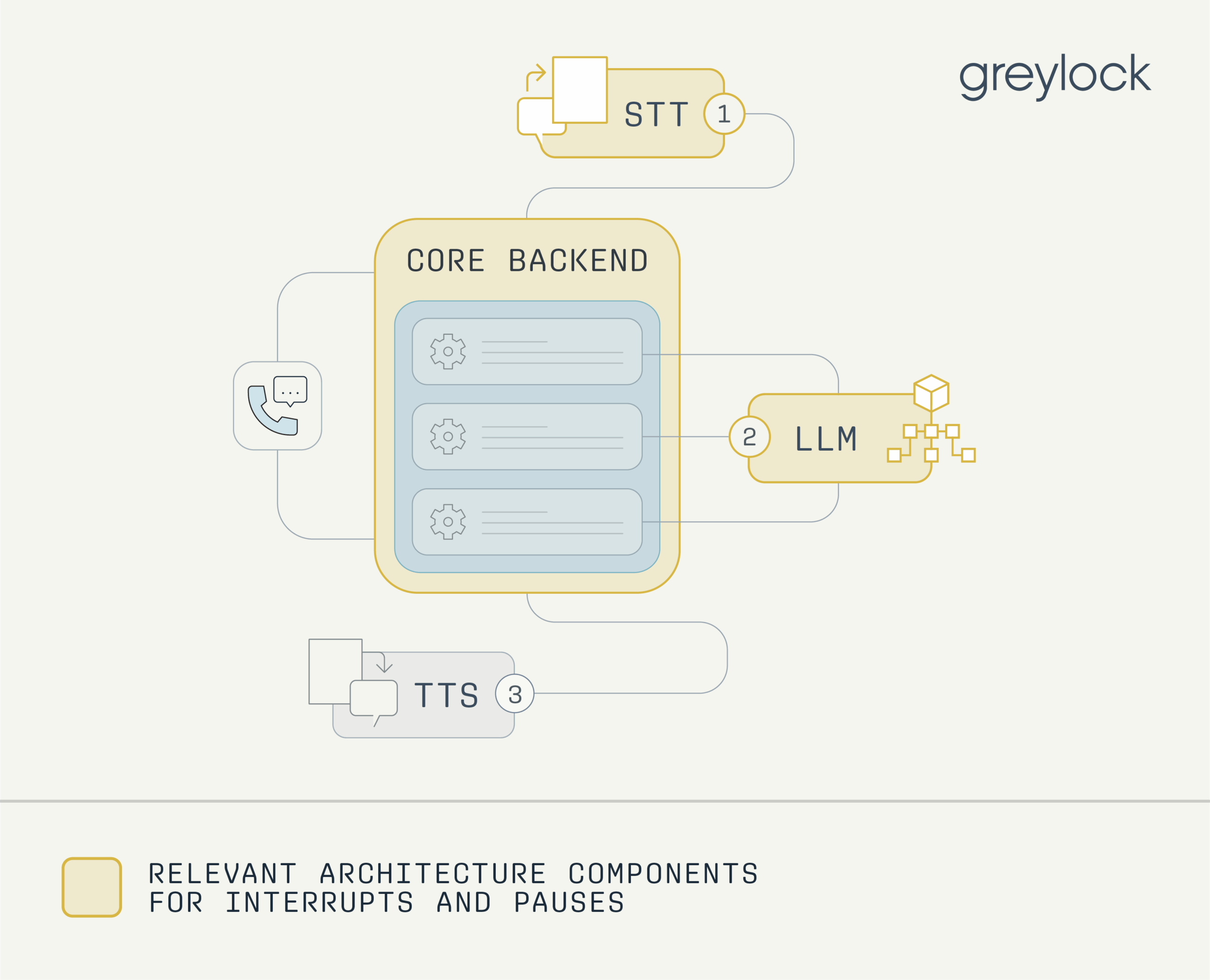
Interrupts and Pauses
Handling interruptions like “mhm,” “yes,” “wait,” “no,” and overlapping speech, as well as distinguishing whether the user is speaking to the agent or to someone else in the room, requires more than just basic voice activity detection. The AI must detect that an interruption has occurred, understand what was said during the interruption, and determine whether to pause, revise, or discard its prior response. It also needs to retain context, such as knowing what it was in the middle of saying, and decide whether to resume the original train of thought, shift to the new one introduced by the user, or manage both in parallel. This demands precise real-time calibration and sophisticated state management to track and prioritize conversational threads. These challenges differ meaningfully between half-duplex systems (where only one party can speak at a time) and full-duplex systems (where both parties can speak concurrently), with the latter requiring more advanced handling of overlapping speech and turn-taking.
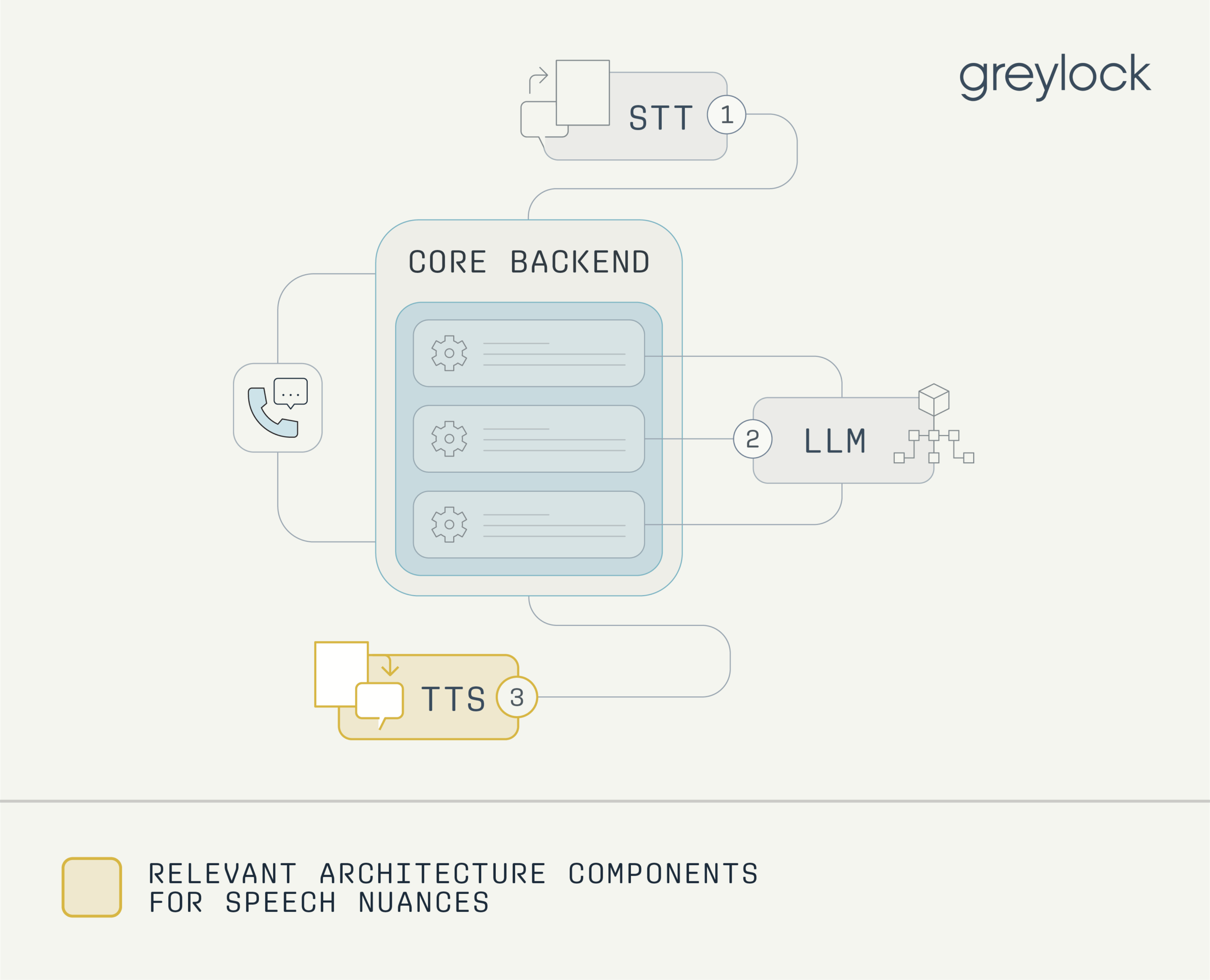
Speech Nuances
Handling accents, uncommon names, phone numbers, addresses, and branded terminology is still error-prone, especially in noisy environments. For instance, a car dealership voice agent should pronounce car brands correctly, but that is not functionality that is automatically encoded in TTS models. Other examples include saying “9-1-1” instead of “nine hundred eleven” or “MIT” instead of “mitt.”
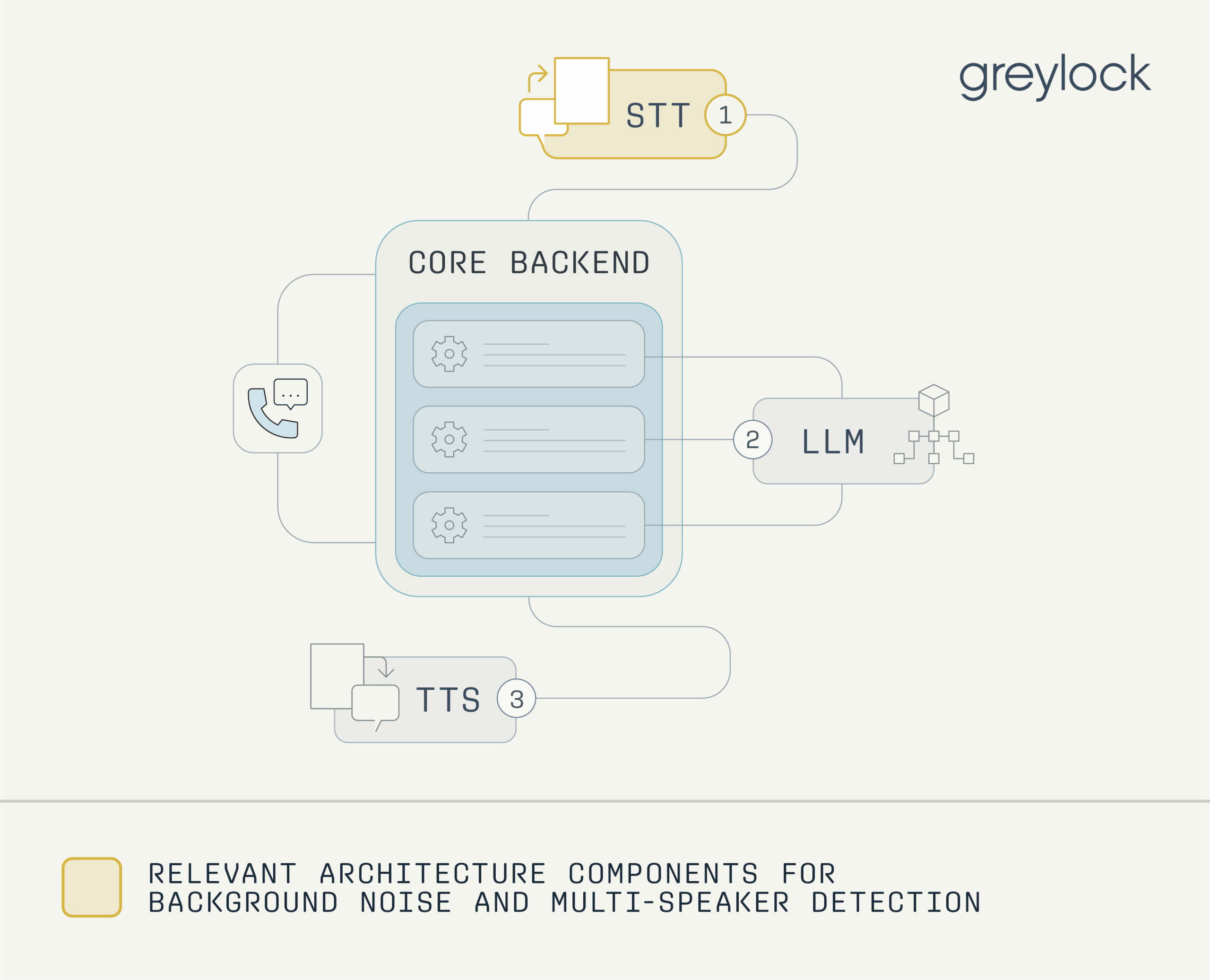
Background Noise and Multi-speaker Detection
Differentiating between a user’s voice and other speakers or environmental noise is critical for accurate transcription and understanding. Real-world environments rarely offer clean audio, and robust diarization remains an unsolved problem in many production settings. These challenges also extend beyond casual conversation. For instance, voice agents must also learn to navigate Interactive Voice Response (IVR) systems, hold music, and other non-speech audio.
These are just some of the challenges that come with building voice agents. It’s not enough for a voice agent to transcribe accurately or sound human. It must also manage ambiguity, hold context, recover from interrupted speech, and handle edge cases with precision. Small flaws in timing, pronunciation, or logic can quickly degrade the user experience in spoken interaction.
Enduring Infrastructure Needs Across the Voice Stack
Regardless of whether teams are building voice agents from scratch, leveraging developer platforms and frameworks, or deploying fully managed applications, certain infrastructure capabilities remain foundational. While today’s systems use STT–LLM–TTS architectures, and may shift toward S2S-native or other architectures over time, a consistent set of needs will endure.
In our conversations with both builders and buyers, we repeatedly heard that reliability, quality, security, and compliance are critical gating factors for production deployment. Builders need confidence that the agents they’re deploying will perform reliably across edge cases, while buyers look for tools to evaluate and monitor agent behavior in real-world environments. These concerns are especially pronounced in highly regulated industries where compliance and security standards are non-negotiable.
Reliability and quality
Regardless of how model performance improves, builders will still need infrastructure to ensure agents behave as expected. In practice, reliability and quality show up in three forms:
- The actual voice itself: It’s important to avoid voice-specific hallucinations such as unintended laughter, mispronunciations of brand names or entities, saying phone and account numbers incorrectly, or incorrectly pronouncing abbreviations.
- The conversation content, context remembered, and actions taken: It’s also important to ensure that agents consistently interpret, respond, and execute the correct steps across a wide range of conditions and edge cases. Platforms like Braintrust enable automated evals for agents, allowing teams to quickly test across prompts and multi-turn conversations.
- The flow of conversation and stream reliability: Voice agents need to avoid awkward pauses, cutoffs, or interruptions in turn-taking. Equally important is the underlying stream reliability, including handling issues like dropped packets, reconnects, and jitter. Regardless of model performance, these lower-level concerns, though often overlooked, can materially degrade perceived voice agent quality and responsiveness.
Together, these capabilities enable voice agents to operate in highly regulated environments like financial services and healthcare, where security and compliance concerns are especially important.
Conclusion
Voice is becoming an increasingly powerful interface for software, but building high-quality voice agents remains technically challenging. From orchestration and latency to real-time audio handling and compliance, the challenges span the full stack—and the solutions do too. Whether teams are operating at the infrastructure, developer framework, or application layer, the bar for production-readiness is high.
At Greylock, we invest time in deeply understanding the technical architecture of voice systems. Doing so allows us to better empathize with engineering challenges, assess product depth with greater rigor, and stay ahead of shifts in the voice stack.
We’re excited to continue learning from teams working at the forefront of voice infrastructure and agentic voice applications. If you’re building in this space, we would love to connect. You can reach me at sophia@greylock.com.
Thanks to Timothy Luong, Dave Smith, Catheryn Li, Andrew Chen, Ben Wiley, Arno Gau, Jason Risch, Jerry Chen, Corinne Riley, and Christine Kim for their thought partnership.